Method
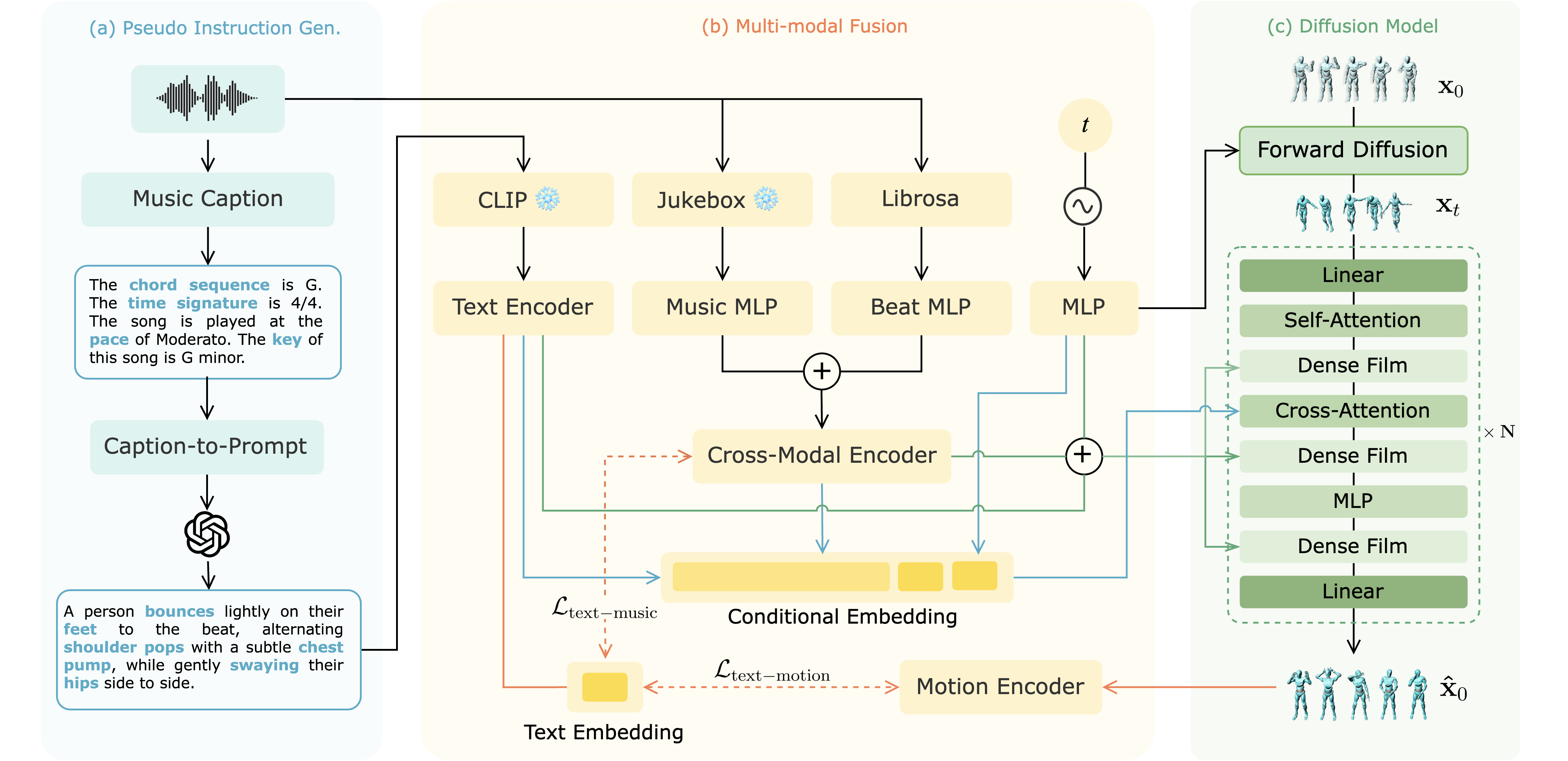
Music-to-dance generation aims to synthesize human dance motion conditioned on music input. Despite recent progress, significant challenges remain due to the semantic gap between music and dance motion, as music offers only abstract cues, and lacks explicit physical movement descriptions. The challenge is further amplified by the scarcity of paired music and dance data, which restricts the model's ability to learn diverse dance patterns. These limitations highlight the need for additional semantic guidance beyond the musical signal. In this paper, we propose DanceChat, a novel framework that leverages a Large Language Model (LLM) as a pseudo-choreographer to generate structured textual dance instructions from musical descriptors, using language as a semantic anchor to bridge the music-motion gap. DanceChat consists of four components: a Dance Instruction Generation module that transforms musical attributes into LLM-derived textual guidance; a Cross-modal Feature Integration module that hierarchically fuses music, beat, and text into a unified conditional embedding; a Language-Mediated Alignment Regularization that structures cross-modal correspondence between music and motion via text, without requiring strict text-motion supervision; and a Diffusion-based Motion Synthesis module. Extensive experiments on AIST++ dataset show that DanceChat outperforms state-of-the-art methods both qualitatively and quantitatively.